By ribbon @
2025-12-21 17:39
Proxmox では、いくつか標準でコンテナイメージが用意されています。その中には openSUSE もあります。ただ、存在しているのは 15.6 で、16.0 はありません。しかし、コンテナソフトの開発をしている、Linux Containers のサイトには、openSUSE 16.0 のイメージが用意されていました。そこで、それを使って openSUSE 16.0 のコンテナイメージをインストールしてみることにしました。
コンテナイメージは https://images.linuxcontainers.org/ にあります。その中に openSUSE 16.0 があります。
opensuse 16.0 amd64 default
というエントリの所にリンク (2025/12/21 では 20251216_04:20) がありますので、そのリンクをクリックします。すると、ファイルの一覧が表示されますので、その中から rootfs.tar.xz をダウンロードします。このファイルを、たとえば opensuse16.tar.xz というファイルに改名して、proxmox が動いているサーバの /var/lib/vz/template/cache に配置します。
追記(2025-12-30)
インストールはできるのですが、ネットワーク関係がかなり変です。インストール時に固定IPアドレス指定にしたのに、起動してみると DHCP でアドレスを取ってきます。NetworkManager の類も入っていないので、ネットワーク関連はまだきちんとできていないのかもしれません。
By ribbon @
2025-06-01 21:21
openSUSE の Proxmox LXC コンテナで、一般ユーザで ping を使うと、
ping: socktype: SOCK_RAW
ping: socket: Operation not permitted
ping: => missing cap_net_raw+p capability or setuid?となって、動きません。しかしこれは、https://blog.ssrf.in/post/ping-does-not-require-cap-net-raw-capability/ に書いてあるように、カーネルパラメータを調整することで、通常通り使えるようになります。実際に、
# sysctl -w net.ipv4.ping_group_range="0 65534"
と入力してみたら正しく動くようになりました。https://hanaokaiwa.hatenablog.jp/entry/2024/06/17/120533 に情報がありました。
Category
openSUSE ,
Tips ,
サーバ ,
デスクトップ |
受け付けていません
By ribbon @
2025-04-04 23:04
openSUSE で動かないので、では、本家本元の Red Hat Enterprise Linux ではどうなのか、を調べてみました。RHEL では IPaddr2 からのメッセージは ocf_log という関数を使っているようで、add_interface() 関数内にある ocf_log に少し細工をして、実行コマンドと引数が表示されるようにしてみました。すると、
4月 04 21:38:17 rh9-a IPaddr2(ClusterIP)[467709]: INFO: Adding inet address 192.168.3.179/24 with broadcast address 192.168.3.255 to device ens18 ip -f inet addr add 192.168.3.179/24 brd 192.168.3.255 dev ens18
と表示されていたんですね。つまり、RHEL では ip コマンドを使って IP アドレスを設定していると。
2025/4/5 追記
Apr 05 20:59:41 clvm-a root[7827]: ip_served cur_nic=,IP_CIP=yes,OCF_RESKEY_ip=192.168.3.169
と言うトレース結果が。あれ、IP_CIP は IP アドレスじゃなくて yes が入っている! RHEL だとここには何も入らないか、IPアドレスのどちらか。なので、IP_CIP に yes が入ることがおかしい。でソースを読むと、IP_CIP が 空 じゃなくて、 ip_status が no だとすると、iptables を呼び出す模様。どうやら IP_CIP が yes なので誤動作した感じ。
By ribbon @
2025-03-23 13:13
openSUSE でSLES のマニュアルを見ながら、クラスタのテストをしています。clvm 環境ができたので、今度は仮想IP のテストをしようとしたらハマりました。
仮想IP の定義後、ノードを再起動すると、syslog に
Mar 23 12:28:31 clvm-a IPaddr2(vip)[3495]: ERROR: iptables failed-'\n\nTryiptables -h’ or ‘iptables –help’ for more information.\nocf-exit-reason:iptables failed\n ]
調べて見たところ、crm から呼び出している IPaddr2モジュールの中で、iptables を呼び出し、それがエラーを出していました。どうも、openSUSE 15.6 にインストールされている iptables バージョン1.8.7 ではクラスタ関係の機能が無いのですね。それで動作しなかったという次第。
さて、どう対処したものか。
Category
openSUSE ,
SLES ,
サーバ |
受け付けていません
By ftake @
2024-07-13 16:26
これまで自宅用の VPN はルーターの機能の L2TP/IPSec を使っていました。しかしながら、Android 12から L2TP/IPSec が使えなくなったり、もともと接続元のネットワーク環境次第で接続できないという制約もあり、VPN を WireGuard に乗り換えることにしました。
WireGuard は Linux カーネルに組み込まれている VPN プロトコルで、特にセキュリティとパフォーマンスを売りにしています。
構成はこんな感じです。VPN 接続用の IP アドレスは固定です。
自宅側
ルーター
ヤマハのダイナミックDNSサービスで IP アドレスを引ける
VPNサーバー(ファイルサーバー)
openSUSE Leap 15.5
LAN側アドレス (eth1): 192.168.10.2(インターネットには直接つながってない)
VPN側アドレス: 192.168.2.1
ポート: 51820
リモート側
Android 14 スマートフォン
Android 13 タブレット
openSUSE Leap 15.6 ノートPC
秘密鍵・公開鍵を作成する
VPN に参加するサーバーとクライアントそれぞれの秘密鍵・公開鍵を作ります。openSUSE が動いている PC で以下のコマンドでそれぞれ作成します。
wg genkey | tee privatekey | wg pubkey > pubkeyprivatekey と pubkey に秘密鍵と公開鍵それぞれが保存されます。合計3回実行することになります。
VPNサーバー側の設定
今回の説明の範囲外ですが、ルーターでポートフォワーディングの設定をしておきましょう。必要なポートはUDP 51820です。192.168.10.2 に転送するようにしておきます。
まずは VPN サーバー自体のネットワーク設定です。WireGuard そのものにはプロトコル上、サーバーとクライアントという関係はなく、どちらもサーバーでありクライアントなシンプルな構成です。後は WireGuard をどのような用途で使うかによって設定が変わってくるため、WireGuard の説明を見るときに、用途を意識してドキュメントを見ないと混乱するので注意が必要です。
今回は自宅で常時起動しているファイルサーバーを VPN サーバーの役割を持たせて、自宅のネットワークにつなぎたい端末からこのサーバーに繋いで使用することにします。ここからはいつもの Arch Wiki に感謝ですが、「特定のユースケース: VPN サーバー」 を見ることで、この用途の設定方法がわかります。
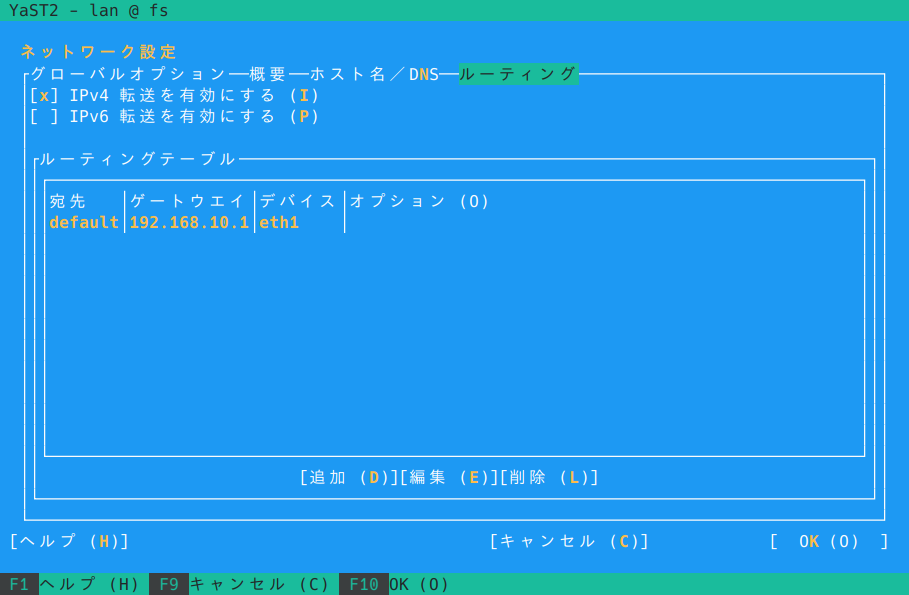
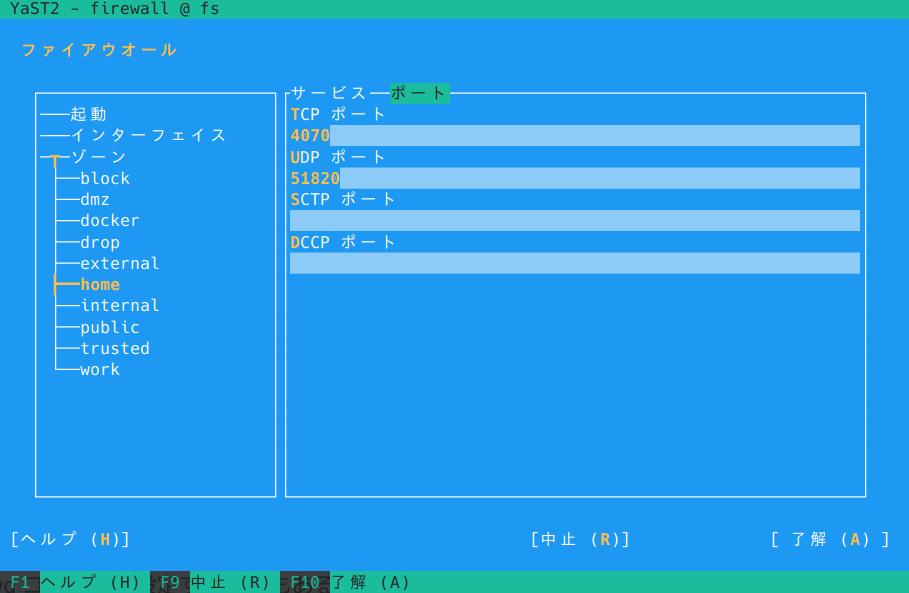
はじめに、転送とファイアウォールの設定です。YaST でやってしまいましょう。
YaST > 「ネットワーク設定」 > 「ルーティング」を開き、「IPv4 転送を有効にする」をON
YaST > 「ファイアウォール」 で使用しているゾーンで「ポート」 > 「UDP ポート」 に 51820 を追加
次に、WireGuard の設定をしていきます。wg コマンドで設定する方法もあるのですが、設定ファイルを直接作成するのが手っ取り早いです。
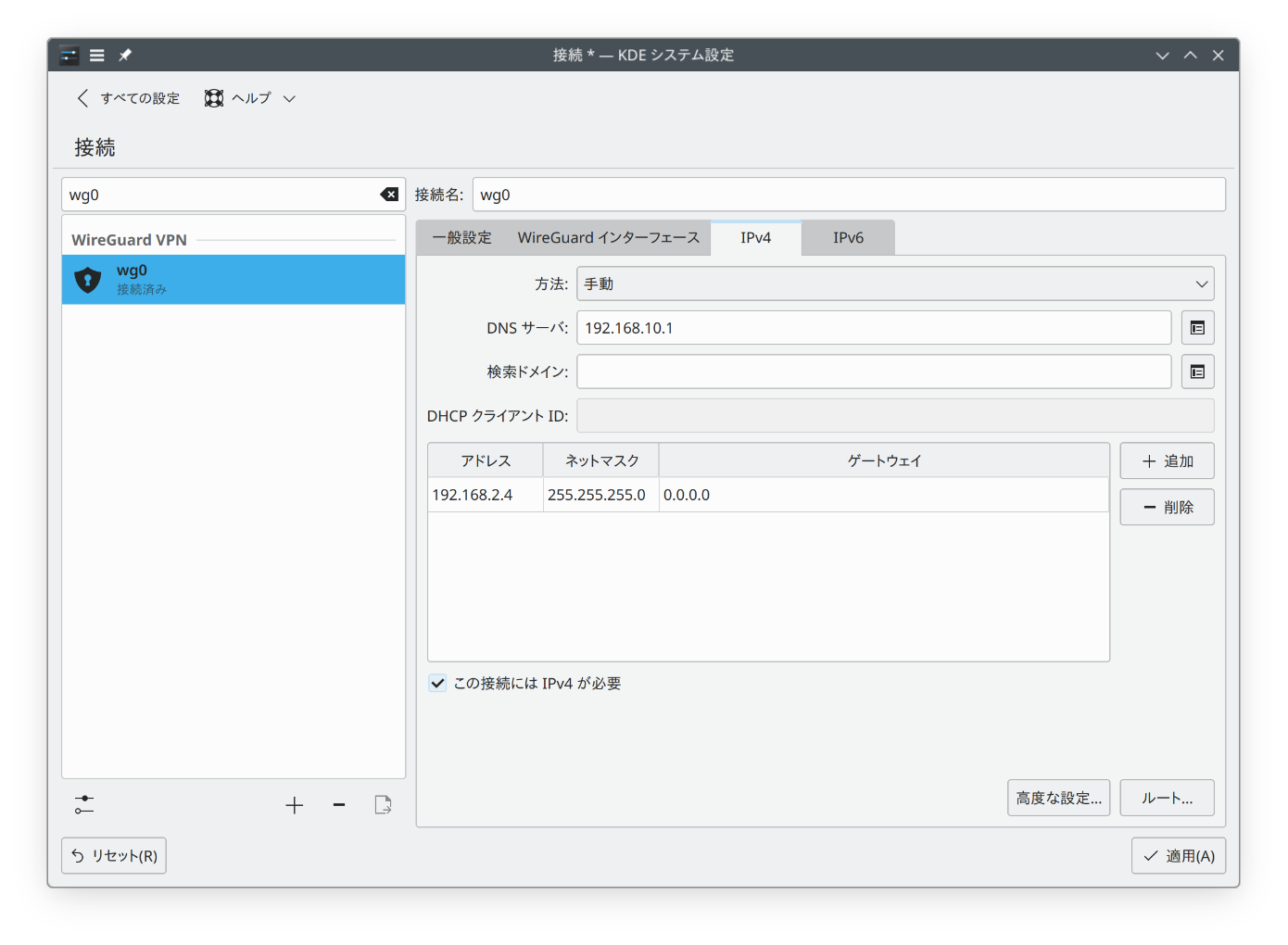
/etc/wireguard/wg0.conf
[Interface]
この設定から、VPN 用のインタフェース wg0 を作成します。Systemd を使用して、起動時に WireGuard インタフェースを立ち上げる便利スクリプトの wg-quick を使います。
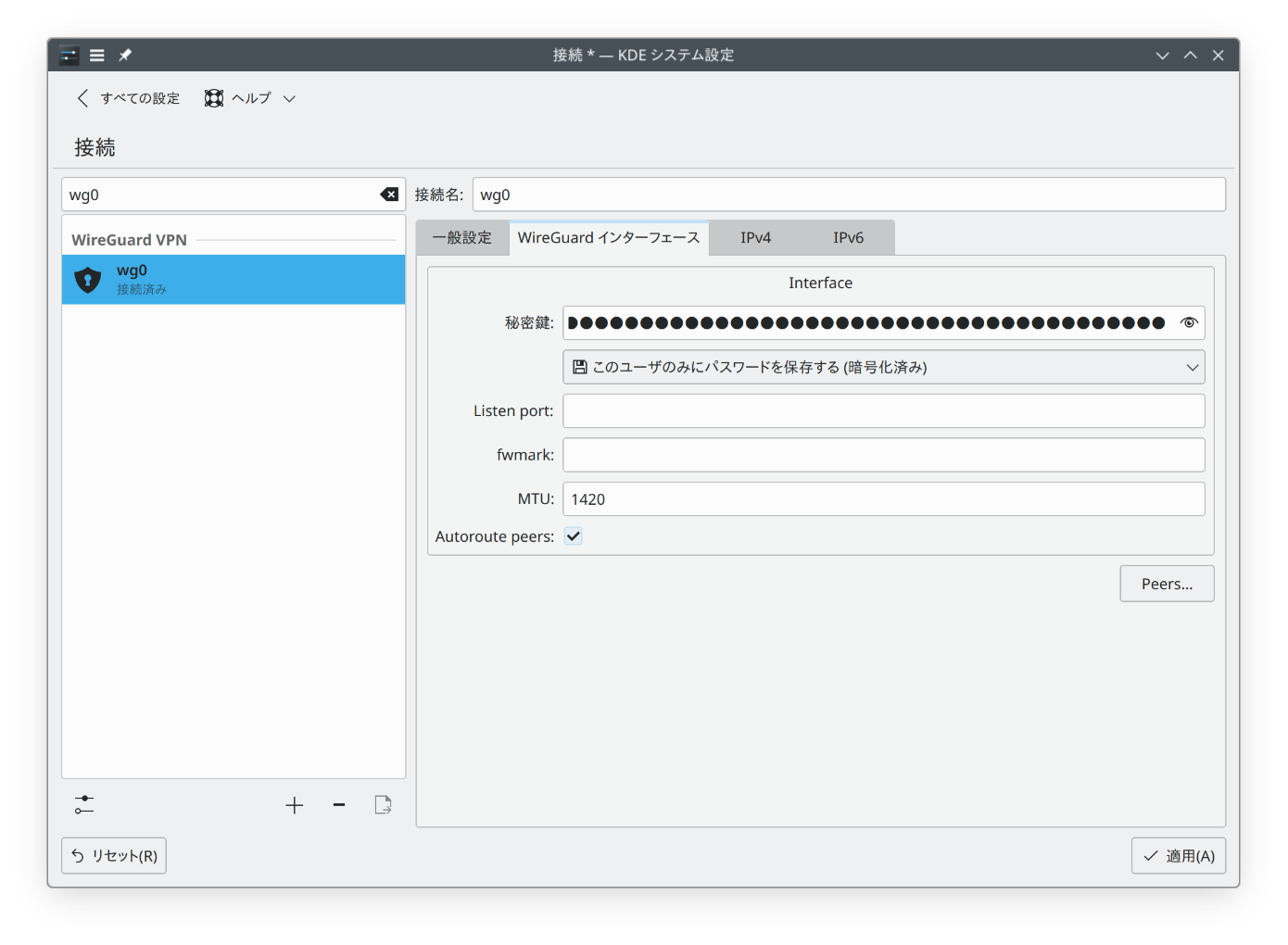
systemctl enable --now wg-quick@wg0クライアントの設定―openSUSE Leap 15.6
NetworkManager の接続の追加に WireGuard があり、これで接続できます。入力する必要の値は
openSUSE Leap 15.6 ノートPC 用の秘密鍵
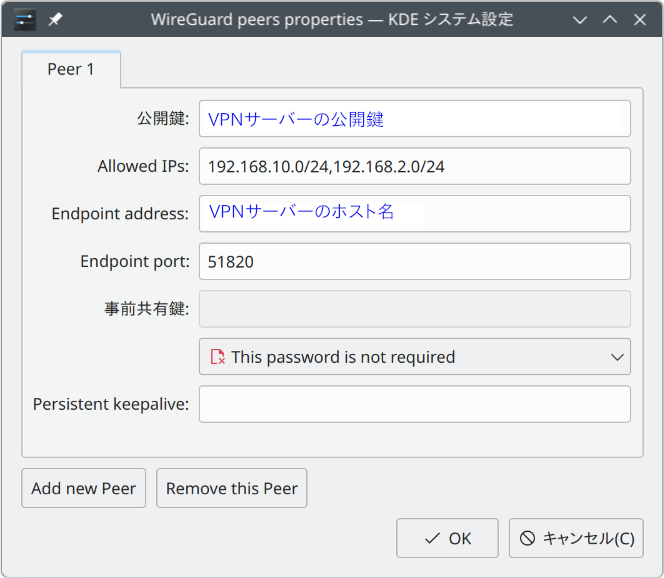
ピア(接続相手: つまり、この場合サーバー)の設定
VPNサーバーの公開鍵
Allowed IPs (VPN を通して通信するアドレスレンジ)
LANとVPNのアドレスレンジ: 192.168.10.0/24, 192.168.2.0/24
自宅LAN経由でインターネットに出たい場合は 0.0.0.0/0 を指定して、全部を VPN 経由にすることも可能
クライアントの設定―Android スマートフォン
Wireguard の接続アプリは Play Store から入手できます。NetworkManager と同様に手入力でもよいのですが、以下のようなファイルを PC 上で作成して QR コード化して送ることもできます。
[Interface]
Address = 192.168.2.3/24
PrivateKey = Android端末の秘密鍵
DNS = 192.168.10.1
MTU = 1420
[Peer]
PublicKey = VPNサーバーの公開鍵
AllowedIPs = 192.168.10.0/24, 192.168.2.0/24
Endpoint = 外からアクセスできるルーターのホスト名:51820ファイル名を android-phone.conf とすると、QR コードは次のようにして作成できます。
qrencode -t ansiutf8 < android-phone.conf
qr コマンドでも同じことができます。
Category
openSUSE ,
サーバ |
受け付けていません
By Syuta Hashimoto @
2023-12-21 08:00
さて、毎度ながらの説明ですが、ALP (Adaptive Linux Platform)は、SUSEとopenSUSEで開発している次世代OSのベースです。イミュータブルで軽量な仕様となっています。
この冬発売のGeeko MagazineにインストールとCockpitというブラウザから管理できるアプリの体験記を書いていますので、ぜひ皆さん試してみてください。
今日は19日の記事 の続きで、alpで動かしたgrafana workloadの制御コマンドを見てみたいと思います。
grafana-container-manage.sh create
grafanaコンテナを作成します。
grafana-container-manage.sh install
grafanaコンテナを動かすのに必要なファイル類をホストの/usr/local/binや/etcにインストールします。
スクリプト内の処理は、ホストのルートをマウントして、label-installというスクリプトを実行していました。
grafana-container-manage.sh start
grafanaコンテナをスタートします。
grafana-container-manage.sh uninstall
installコマンドでインストールしたファイル類などを削除します。こちらもスクリプト内の処理はホストのルートをマウントして、label-uninstallというスクリプトを実行していました。
grafana-container-manage.sh stop
grafanaコンテナをストップします。
grafana-container-manage.sh rm
grafanaコンテナを削除します。
grafana-container-manage.sh rmcache
garfanaイメージを削除します。内部で実行されるコマンドは、podman rmiです。
grafana-conatiner-manage.sh run
grafanaコンテナを実行します。
grafana-container-manage.sh bash
grafanaコンテナ内のbashを実行します。
grafana-container-manage.sh logs
grafanaコンテナのログを表示します。
コンテナのライフサイクルがわかっていれば、各コマンドの意味がわかるかと思います。
uninstallを実行すると、当然grafana-container-manage.shも削除されます。再び使うためには、19日の方法でイメージのinstallラベルを実行します。
# podman container runlabel install registry.opensuse.org/suse/alp/workloads/tumbleweed_containerfiles/suse/alp/workloads/grafana:latestまた、rmcacheでイメージを削除後、createをしようとするとイメージのpullが始まります。まぁ当然ですね。
実行時、runだとgrafanaのコンテナの中のシェルが動いたため、cerateからstartを実行する方法が安全そうでした。
基本的にはpodmanコマンドのラップですが、installなど一部処理を簡単に実行できるようになっているので、ぜひ試してみてください。
By Syuta Hashimoto @
2023-12-19 08:00
さて、毎度ながらの説明ですが、ALP (Adaptive Linux Platform)は、SUSEとopenSUSEで開発している次世代OSのベースです。イミュータブルで軽量な仕様となっています。
この冬発売のGeeko MagazineにインストールとCockpitというブラウザから管理できるアプリの体験記を書いていますので、ぜひ皆さん試してみてください。
ここ何回かalpについて記事を書いていて、やっとわかってきました。SUSE/openSUSEは、ホストとの連携が必要などの単に動かすだけでない処理が必要なアプリのインストールや準備処理を、コンテナに内包して、workloadとして動かす、という戦略をとってるものがります。その時に利用するのが、podmanのlabel付け(実行コマンドにlabelをつける)と、そのlabel名で呼び出すrunlabelオプションです。
今回はgrafanaをマニュアル に従って動かしてみます。
grafanaサーバーのセットアップ
まず、workload内包コンテナを探します。
# podman search grafanaあれ?一覧にworkloadのコンテナが出てきません。直接レジストリ名を指定してみます。
# podman search registry.opensuse.org/suse/alp/workloads/tumbleweed_containerfiles/suse/alp/workloads/grafana表示されました。
では、イメージをpullしてワークロードを実行します。
# podman container runlabel install
registry.opensuse.org/suse/alp/workloads/tumbleweed_containerfiles/suse/alp/workloads/grafana:latest容量があり1分ほど時間がかかりましたが、準備が完了しました。
grafanaのworkloadは、grafana-container-manage.shというスクリプトを用意してくれ、これを使ってコンテナの作成や実行などを行います。
まずは、コンテナを作成します。
# grafana-container-manage.sh createすぐにコンテナが作成されました。
では、コンテナをgrafanaのサーバーと共に実行します。
# grafana-container-manage.sh start今は指示通りコマンドを叩いてるだけですが、それぞれが何をしているかを見てみるのも楽しそうですね。
grafanaクライアントのセットアップ
今回はalpを動かしているホストをクライアントにしようと思います。
クライアントには、以下の2つのパッケージをインストールし、サービスを再起動します。
パッケージのインストール
golang-github-prometheus-node_exporter
golang-github-prometheus-prometheus
サービスの再起動
systemctl restart prometheus-node_exporter.service
systemctl restart prometheus
grafanaでの表示
では、grafanaを設定していきます。
ブラウザからgrafanaにアクセスします。
http://[ALP_HOST_IP]:3000
ログイン画面が表示されるので、ログインします。初期設定は両方ともadminとなっています。ログイン後、パスワード変更画面になりますので新しいパスワードを設定します。
ログイン後画面 ログインしたら、ホストのprometheusからデータを取得します。
上段の真ん中にある「DATA SOURCES」をクリックし、種類の一覧が表示されるので一番上の「Prometheus」を選択します。
Prometheus server URLに、Prometheusを動かしているマシンのurlを指定します。デフォルトでポートは9090です。僕の場合、alpを動かしているホストなのでhttp://192.168.122.1:9090となりました。
ホストのlibvirtのゾーンで9090を開放し、画面下部の「Save & test」ボタンをおすと、Successfullyと出てきました。
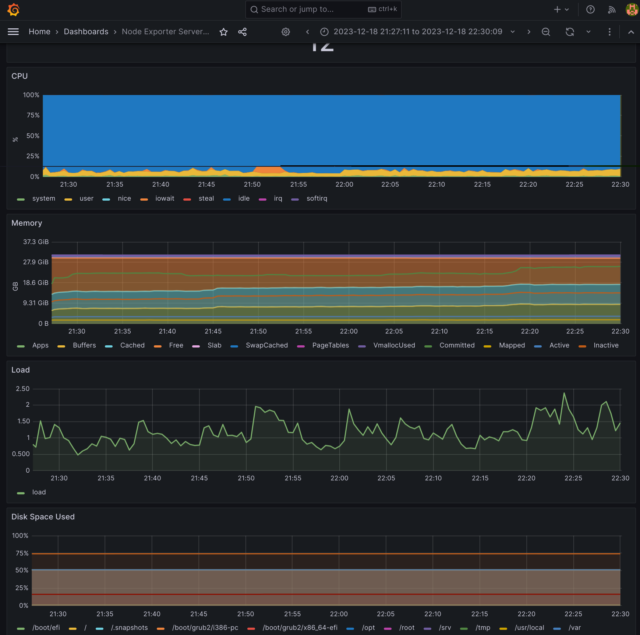
サンプルで用意されているDashboardsを読み込んでみます。マニュアルはバージョンが古いようで、僕が試した時は以下の手順になりました。
左上のハンバーガーメニューから、Dashboardsを選択する
右側にある「New」のボタンをクリックして出てくるドロップダウンから、Importを選択する
Import via grafana.comに、405と入力して「Load」をクリックする
prometheusをクリックして、データソースを選択する 手順通りだと一つのため、それを選択する
設定が読み込まれるので、下の「Import」をクリックする
無事、グラフが表示されました。
Grafanaダッシュボード grafanaを制御するスクリプトには他にもアンインストールやキャッシュ削除などのオプションがありますので、追って紹介しようと思います。