By Syuta Hashimoto @
2020-12-23 01:30
諸事情で、MicroOSのルートにbtrfsの機能でディスクを追加したのですが、balasceを実行しようとすると「read onlyだよ」と警告が。
ユーザ会slackに投げてみた所、武山さんから「transactional-update shellの中ならいけるのでは?」との助言を頂きました。
結論
成功
コマンド
transactional-update shell
transactional-updateそのもののアップデートが行われた後、独自のシェルに移行しました。
transactional update #
この状態で書き込み可能になります。書き込み後、シェルを抜けてrebootすれば反映されるしくみですね。
btrfs balance /
前後の状態を撮り損ねてしまったのですが、無事にbalanceされてました。
transactional-updateの真価はまだ味わえてないので、ロールバック等含め、近いうちにまとめて検証してみたいですね。
そもそも、transactional-update shellが一体何をどうしているのかも追えていない・・・
By ftake @
2020-12-18 01:59
この記事は openSUSE Advent Calendar 18日目です。 残り、あと少しですが、まだ埋まってなく3年連続の完走がピンチ。みなさんご協力下さい。
この内容は小江戸らぐ のオフな集まり2月と、オフだけどオンライン開催だった5月の発表内容でもあります。
ことの始まり
この春、ファイルサーバーを組みました。これまで、写真等の大きめのファイルはデスクトップに置いていましたが、タブレットやスマフォを使用しているとデスクトップを起動しないこともあり、アクセスするにはちょっと不便でした。かといってクラウドに上げるには容量が大きいのが現状です。
このとき、電源の故障で引退した、ちょっと古いけどまだ使える一式(Socket FM2 の M/B, AMD A4-5300 APU, DDR3 8 GBメモリ)があったのと、鹿さん から、使わなくなったファイルサーバー用の MiniITX ケースを頂いたので、これでファイルサーバーを組んでみることにしました。
RAID カード調達
HDD は NAS 用のものを適当に買うとして、1度はRAID 5 や 6 で組んでみたい!ということで、RAID カードを探しました。一般のご家庭(誤変換)では、数万円クラスのカードを使っているかと思いますが、この「ありあわせ構成」には不釣り合いです。安く入手する方法としては、ヤフオクなどでサーバーから抜き取ったものを探す手がありますが、あまりに古いと EFI に対応していなかったり、4 KB セクタや 2TB の壁にあたる可能性があります。また、中古品はキャッシュ保護用のバッテリーが死んでいる可能性もあります。
そこで今回は eBay で3世代前の Adaptec ASR-71605 の新古品を買ってみました。キャッシュ保護用のコンデンサ付き、送料込みで 8500円くらいでした。ドライバはカーネルに入っているのですぐに使えます。
意外と高かったのがケーブルでした。Mini SAS HD から SATA ×4にするもので、Amazon で 2500 円くらいでした。
OS インストール
セットアップに困ることはないはずが、openSUSE 15.1 をインストールすると、なぜかディスプレイドライバが固まります。いろいろ試したところ modeset ドライバを ACPI が有効な状態で使うとダメなようです。今回はディスプレイはほとんど使わないので nomodeset を起動オプションに追加することで回避しました。(modeset ドライバだと、コンソールの解像度がディスプレイにあわせて変わるので良いのですが…)
ファイルサーバーの設定
Samba は入れるだけです。とっても簡単ですね。
Btrfs にしてスナップショットを取るようにしました。このあたりはOSCのスライド や Geeko Magazine を見てください。
iSCSI サーバーは4月に書いた別の記事 で。
バックアップの設定
重要なディレクトリを選んで USB 接続の HDD に1日に1回、Snapper の最新スナップショットからバックアップを取るようにしました。単純に rsync でコピーを取ります。Btrfs のバックアップといえば、ファイルシステムレベルで差分転送をできる btrfs send があります。しかし、ファイルシステムが壊れてしまった場合に、btrfs send を行うとバックアップも壊れる可能性があるのではないかと考え、今回は使用しませんでした。
タイマーとスクリプトはこのような感じです。タイマーの時間は Snapper の実行中にならないように気をつける必要があります。
backup-to-usb-disk.timer
[Unit]
Description=Back up files to USB disk daily
[Timer]
OnCalendar=*-*-* 6:20:00
Persistent=true
[Install]
WantedBy=timers.target
backup-to-usb-disk.service
[Unit]
Description=Back up files to USB disk
[Service]
ExecStart=/usr/local/sbin/backup-to-usb-disk.sh
Type=oneshot
backup-to-usb-disk.sh
#!/bin/bash
set -e
if [ ! -f /var/backup/backupdisk ]; then
echo "Back up disk is not found"
exit 1
fi
# home
snapshot_root=/home/.snapshots
cd $snapshot_root
latest_snapshot=`ls -1 | grep "[0-9]*" | sort -nr | head -n 1`/snapshot/
echo "creating back up of /home/.snapshots/$latest_snapshot"
if [ ! -e $latest_snapshot ]; then
echo "Snapshot directory error"
exit 1
fi
target_dir=/var/backup/home/
rsync -va --delete $latest_snapshot $target_dir
様子見中
Snapper が走る時(おそらく)に btrfs-cleaner がかなり CPU を使うので、試しに Quota 機能を無効にしています。
おわりに
簡単にではありますが、ファイルサーバーを構築したときのいろいろを紹介しました。このファイルサーバーでは、先日書いた Spotify クライアント も動いています。新たな活用を始めたら記事にしたいと思います。
Category
openSUSE ,
サーバ |
受け付けていません
By Syuta Hashimoto @
2020-12-17 01:00
私はKubicでKubernetesを構築しているのですが、Kuibcをアップデートしてkubeletのバージョンが1.19に上がったはずなのにもかかわらず、kubectl get nodeでずっとバージョンが1.18となっていて悩んでいました。
結論
/etc/sysconfig/kubelet に設定されている KUBELET_VERを、1.18から1.19に変更する
調査
パッケージを確認
まず、パッケージがなんのバージョンが入っているかを確認します。
kubic1-host:~ # zypper se kubelet
どうやら、1.17、1.18、1.19、と、いろいろなバージョンが入ってるようです。
今見たら、1.20も入ってますね。
使ってるバイナリを確認
kubic1-host:~ # type kubelet
kubelet is hashed (/usr/bin/kubelet)
ふむふむ。/usr/bin/kubelet、ですね。
こういう実行ファイルはスクリプトの場合があったりするので、種別を調べてみます。
kubic1-host:~ # file /usr/bin/kubelet
なるほど、スクリプトっぽいですね。
中身を確認します。
kubic1-host:~ # cat /usr/bin/kubelet
どうやら、/etc/sysconfig/kubeletの値を参照しているようです。こちらを確認してみます。
kubic1-host:~ # cat /etc/sysconfig/kubelet
なるほど、KUBELET_VERが定義されています。nodeのバージョンが低いときは、ここが1.18となっていましたので、それを1.19に更新しました。
それからKubernetesを起動すると、見事バージョンが1.19にあがってました。
今なら1.20に上がる予感・・・・
メーリングリスト
最近忙しいこともあって、なかなかメーリングリストなどの情報源にあたれず・・・もしかしたら、こういったことはとうに情報共有されていたのかもしれません。また、この設定がKubic独自なのか、一般的なのか、といったことも追いきれておらず。追って調査したいと思います。
そもそもの使い方
アップデートで使い続けるのではなく、折を見て最新プリメイドイメージに乗り換えていく運用が今っぽいのかも・・・・・
Category
サーバ ,
未分類 |
受け付けていません
By ribbon @
2020-12-08 00:02
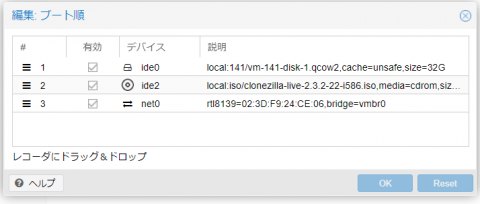
仮想環境プラットフォームとしてとても便利なProxmox VEですが、バージョン6.3が出ています。
変更点は https://pve.proxmox.com/wiki/Roadmap#Proxmox_VE_6.3 にありますが、順当に少しずつ機能が強化されてるという所でしょうか。あと今回は、Proxmox Backup Server との統合機能がメインかな。
地味にモダンなインタフェースになっているところもあります。例えば、今までプルダウンメニューで選択していたブート順の指定が、GUIのドラッグ&度ラップで出来るようになっていたりします。
日本語訳については最新版が反映されていないようです(画面ではテスト環境なので最新版になってますが、まだバグがありますね)。
そのほか、クラスタ回りとかストレージ回りで少しずつ改良がされているようです。ただ、openSUSE をゲストOSにしてテストするような場合にはあまり影響はないようです。
Category
Tips ,
サーバ ,
仮想化 |
受け付けていません
By Syuta Hashimoto @
2020-12-07 00:10
某LUGで、Kubernetesのメモリ使用量を気にされていたので、測ってみました。
結論
masterノードはKubernetes起動後、1.3G前後のメモリを使用。workerは、コンテナを動かせば動かしただけメモリを使用。15pod程度では、2つのworkerでそれぞれ1G使わない程度でした。
方針
KVM上にKubicを展開して、そこでKubernetesを動かします。
VMの起動のみの状態、Kubernetesを起動した状態、いくつかのpodを動かした状態、で、freeや、topのメモリ使用量上位10のプロセスを拾ってみます。
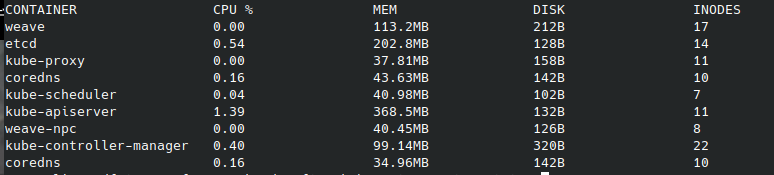
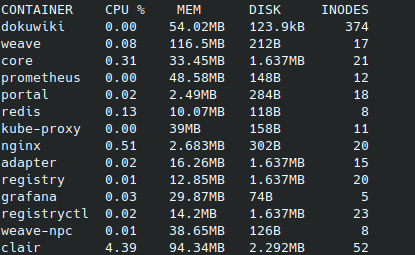
また、Kubernetes起動後はcrictl statsの結果も見てみます。今回、IDを名前で置き換えていますのでご注意下さい。(通常のcrictl statsですと、IDのみの表示となり名前は表示されません。)
環境
Kubernetes KVM上で動かす OSはKubic CPU数 master 2 worker 1 メモリ それぞれ 3G Kubernetes 1.19.4 ホストopenSUSE 15.2 CPU Ryzen 3900 メモリ 32G Kubic ・・・openSUSEプロジェクトで開発している、Kubernetes専用OSです。Tumbleweedをベースにしていて、Kubernetesを動かすことに焦点を絞ったパッケージ構成&システム設定。プリビルドなイメージが毎日のように公開されるため、ignitionなどの初期設定ツールを使って手早く最新Kubernetesを展開できます。
Ryzen 3900・・・コア数12なので、VMは結構たてられます。目指せおうちクラウド。
ちなみに、saltstackのマスター用VMを別途立てていて、各ゲストは基本的にそこから制御しています。(今回のコマンド実行は直接各ゲストで行いました。)
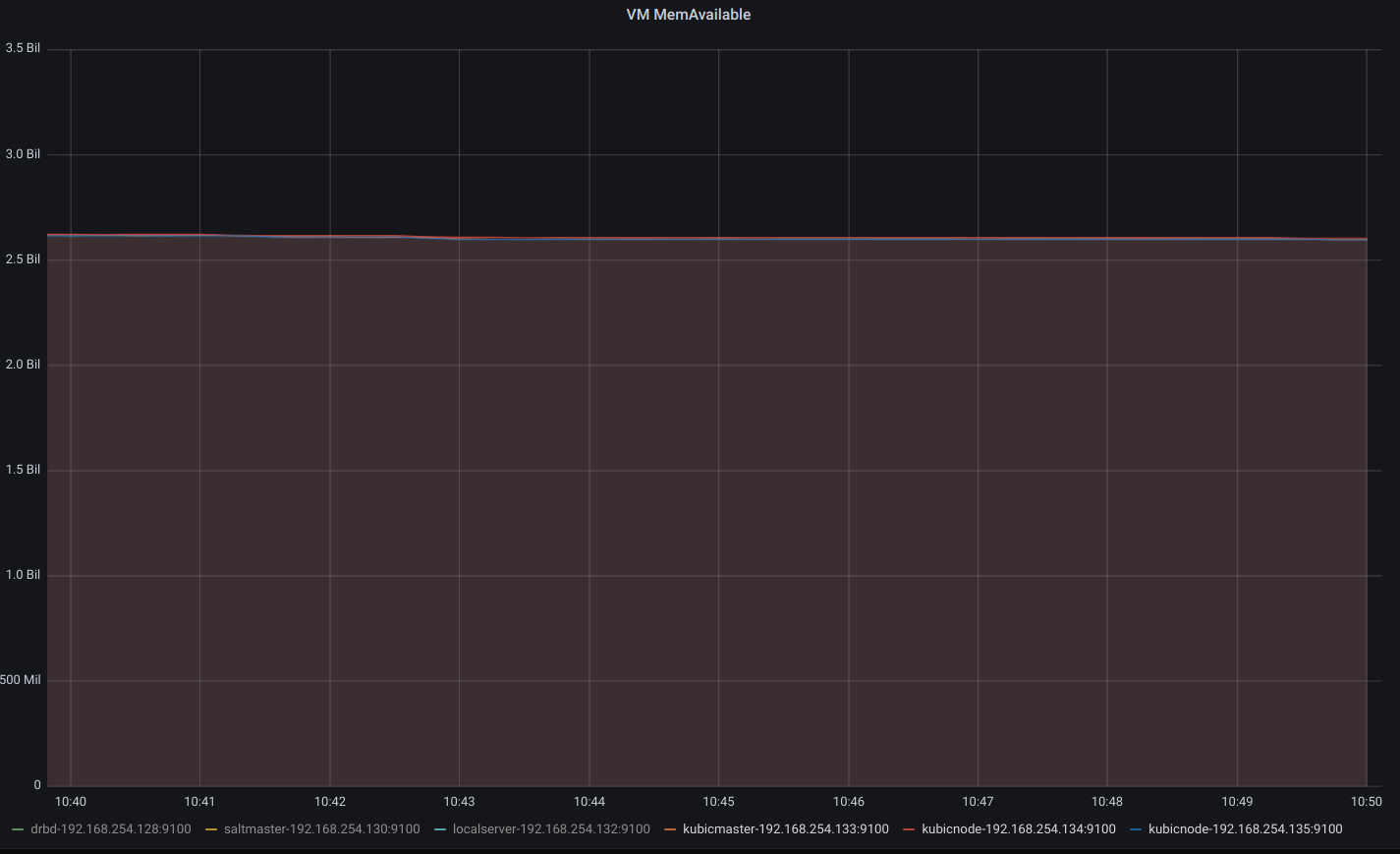
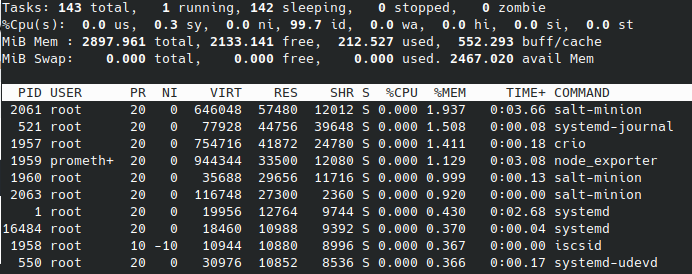
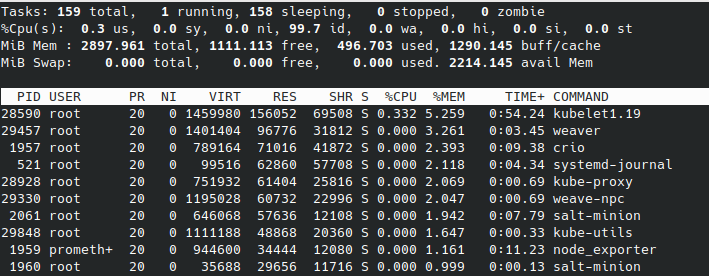
VMの起動のみ
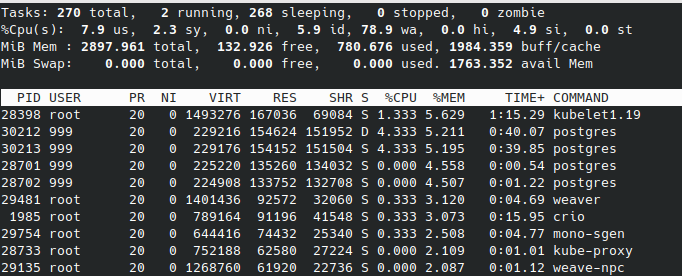
master
worker1
worker2
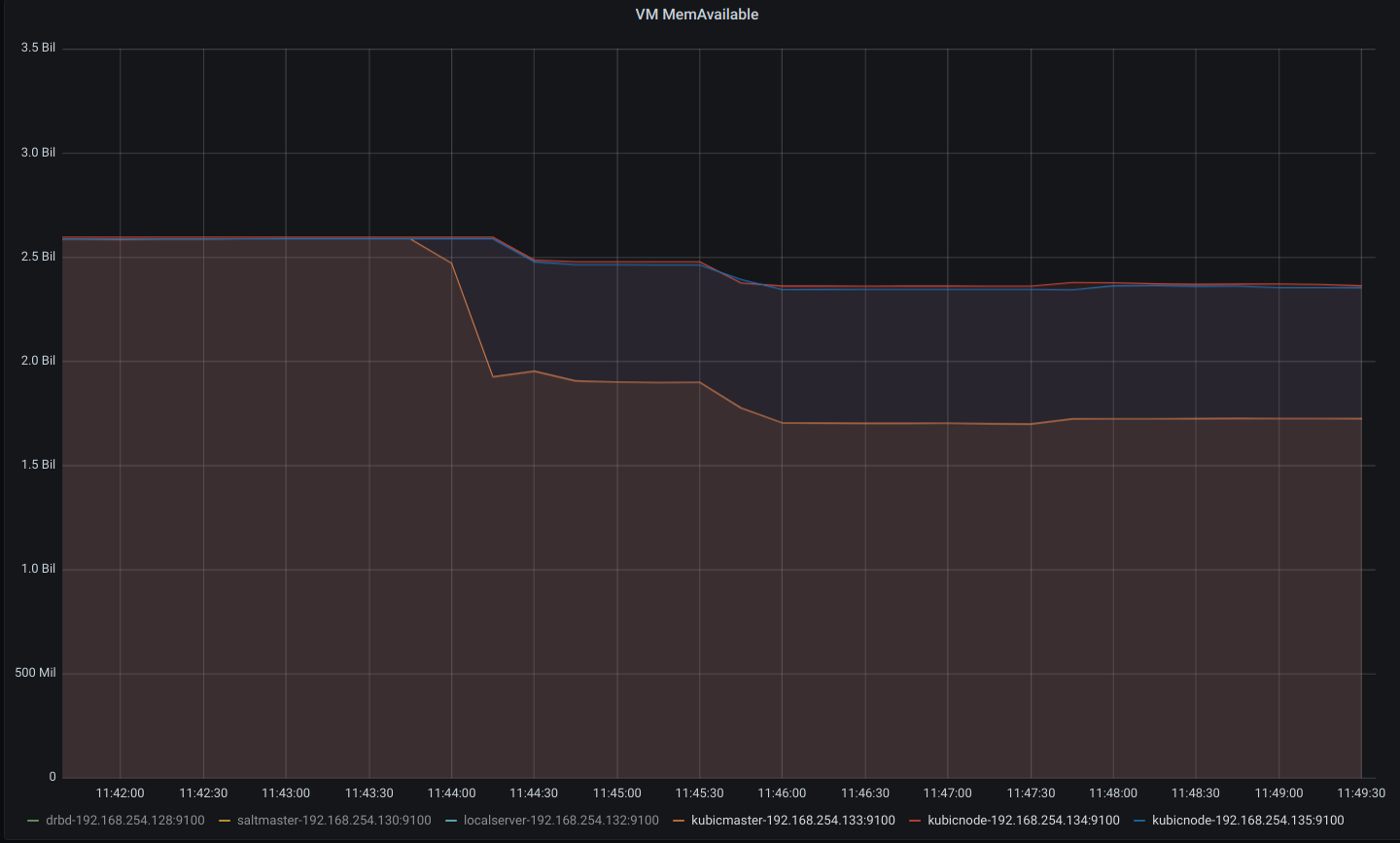
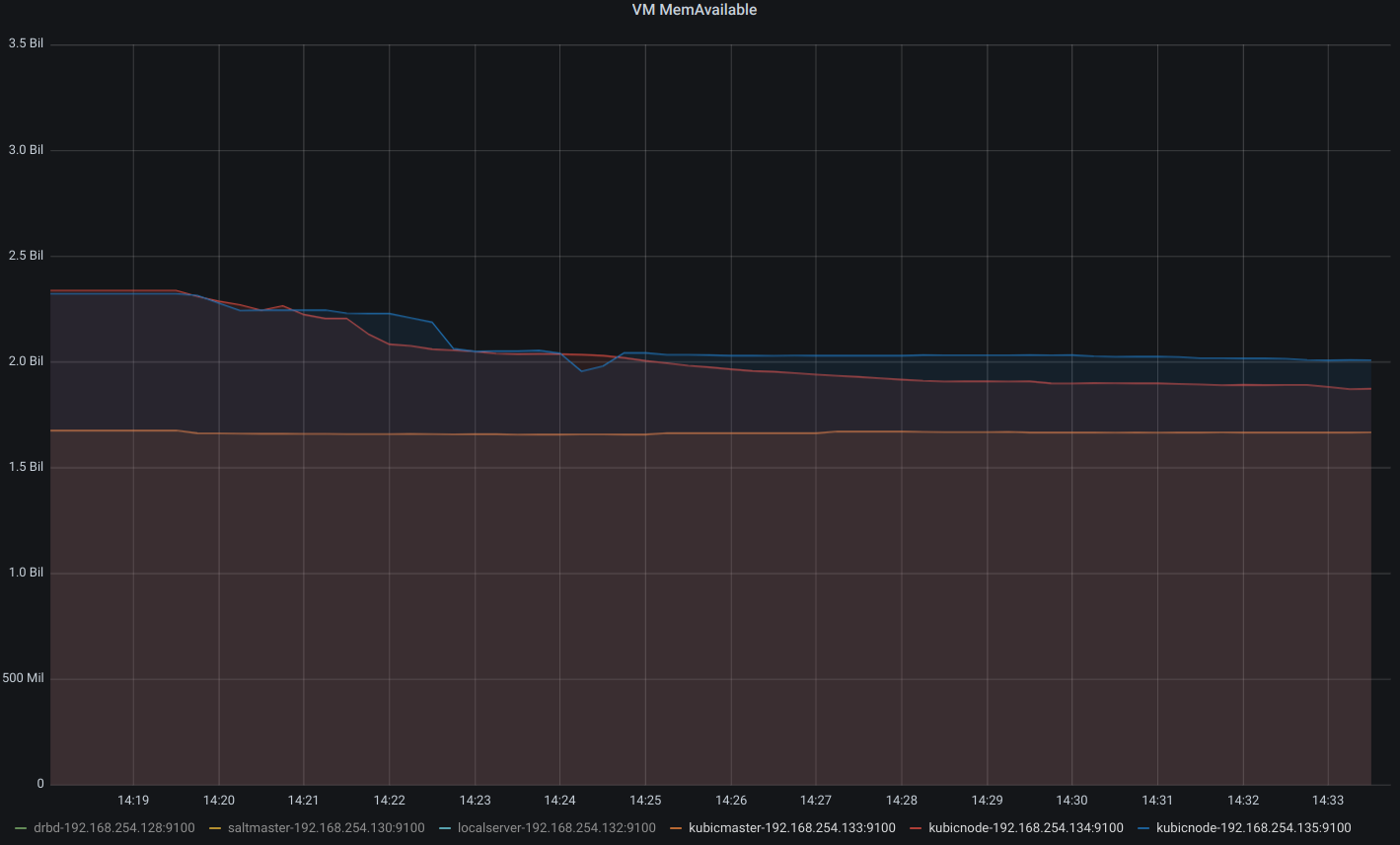
利用可能メモリが、3台とも2.5G程度であることがわかります。
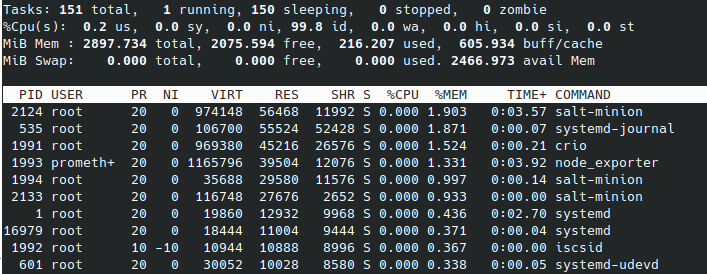
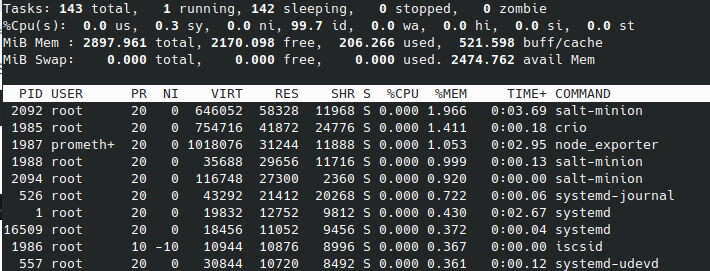
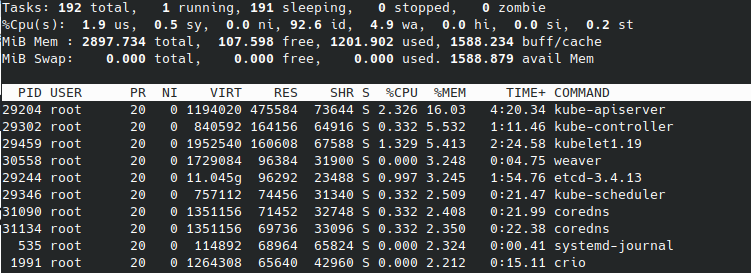
Kubernetes起動後
Kubernetesとネットワークアドオンのweaveを起動します。
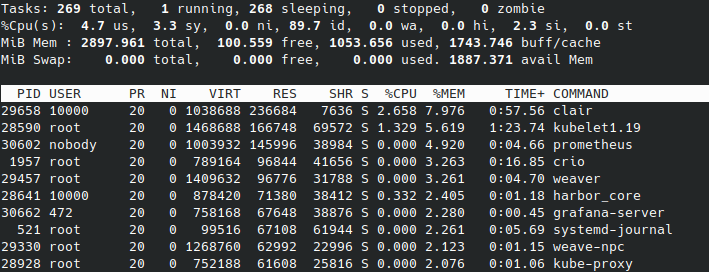
master
worker1
worker2
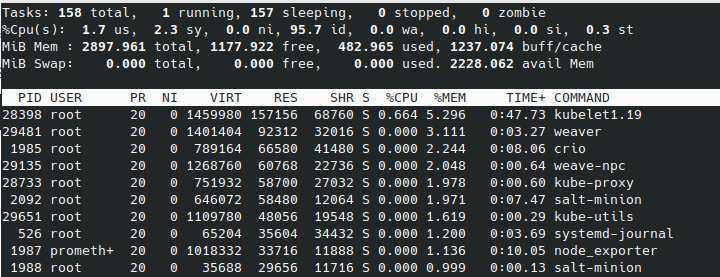
masterがさらに1G程使用しました。workerは数百程度の使用にとどまっています。
podを幾つか起動した後
15個程podを走らせてみます。
走らせたサービスは、Promeheus、Grafana、DokuWiki、Nextcloud、Harborなどです。
master
worker1
worker2
masterの使用量はほとんどかわりませんが、動いたpod分、両workerのメモリが使用された感じです。
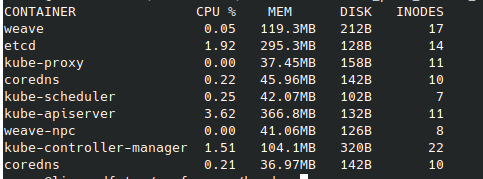
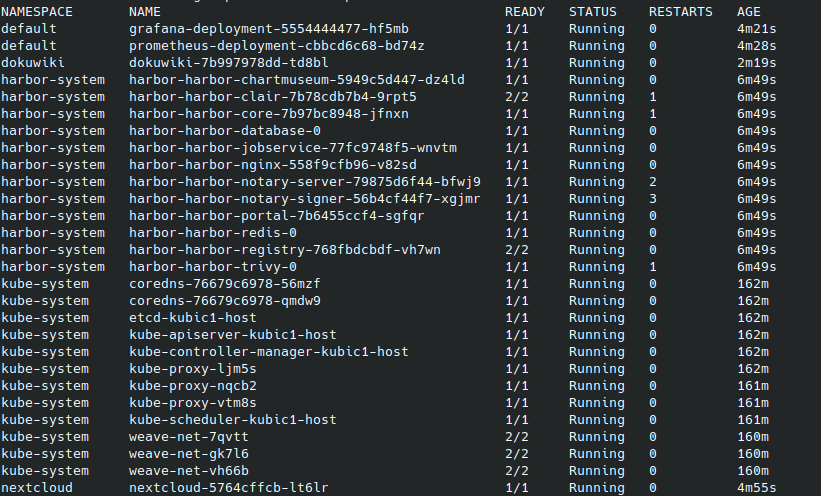
参考までに、pod一覧です。
感想
色々と検証しているときは、clairが1G以上メモリを使ったりしていましたが、今回計測しているときは100Mいかないぐらいでした。当然ですが、podの起動だけでなく、実際に使ってみた時のメモリ使用量なんかが実運用上では参照値になると思います。
まだ、プロセスやコンテナの動作と使用メモリとの関連を掴みきれてないので、追って調査してみたいと思います。コンテナのメモリとディスクの関連も。
なお、今回動かしたサービスの殆どはiscsiのPersistentVolumeに接続しています。このあたりの方法も消費リソースと関わっていそうですね。
Kubernetesってメモリ使うんだよなー、よし、各ノードに6G割り当てるか、とかやっていたのですが、今回の計測で今の所3Gでも大丈夫なことがわかったので、設定を変更しました。やはり適切な設定は適切な計測から、ですね。ちなみに、Kubernetesでpodを動かす時に、CPU使用率やメモリ使用量の上限などを設定できます。このあたりについてもおいおい見ていきたいと思います。
Category
openSUSE ,
Tips ,
サーバ |
受け付けていません
By ribbon @
2020-12-04 00:02
結論から先に書きます。Proxmox VEのLXC コンテナでX をぅこかすことは出来ませんでした。
コンソールとしてSPICEクライアントやxterm.js も指定できるので、出来るかなと思ったのですが、そうは問屋が卸しませんでした。
Xはインストール出来ます。しかし、xinit で起動してみると、 /dev/tty0 がないと言ってきて起動しません。確かに、/dev/ 配下を見ると、
ls -l
total 0
crw–w—- 1 root tty 136, 0 Nov 20 10:10 console
lrwxrwxrwx 1 root root 11 Nov 20 10:03 core -> /proc/kcore
lrwxrwxrwx 1 root root 13 Nov 20 10:03 fd -> /proc/self/fd
crw-rw-rw- 1 nobody nobody 1, 7 Nov 11 08:28 full
lrwxrwxrwx 1 root root 25 Nov 20 10:03 initctl -> /run/systemd/initctl/fifo
lrwxrwxrwx 1 root root 28 Nov 20 10:03 log -> /run/systemd/journal/dev-log
drwxrwxrwt 2 nobody nobody 40 Nov 20 10:03 mqueue
crw-rw-rw- 1 nobody nobody 1, 3 Nov 11 08:28 null
crw-rw-rw- 1 root root 5, 2 Nov 20 2020 ptmx
drwxr-xr-x 2 root root 0 Nov 20 10:03 pts
crw-rw-rw- 1 nobody nobody 1, 8 Nov 11 08:28 random
drwxrwxrwt 2 root root 40 Nov 20 10:03 shm
lrwxrwxrwx 1 root root 15 Nov 20 10:03 stderr -> /proc/self/fd/2
lrwxrwxrwx 1 root root 15 Nov 20 10:03 stdin -> /proc/self/fd/0
lrwxrwxrwx 1 root root 15 Nov 20 10:03 stdout -> /proc/self/fd/1
crw-rw-rw- 1 nobody nobody 5, 0 Nov 15 23:26 tty
crw–w—- 1 root tty 136, 0 Nov 20 10:03 tty1
crw–w—- 1 root tty 136, 1 Nov 20 10:03 tty2
crw-rw-rw- 1 nobody nobody 1, 9 Nov 11 08:28 urandom
crw-rw-rw- 1 nobody nobody 1, 5 Nov 11 08:28 zero
となっていて、/dev/tty0 がありません。そこで以下を試してみました。
/dev/console を /dev/tty0 に ln しようとしたのですが、 ln -s でやってみたのですが、xinit を動かしたときに mknod tty0 c 136 0 でデバイスファイルを作ろうとしたのですが、 でした。これで行き止まり。
ちなみに、他のディストリビューションも見てみましたが、結果は同じ。そもそも tty0 がないところから同じでした。
というわけで、残念ながらコンテナ内でXを動かすのには失敗しました。
Category
openSUSE ,
Tips ,
サーバ ,
デスクトップ ,
仮想化 |
受け付けていません
By ribbon @
2020-12-03 00:02
手軽な仮想化環境 Proxmox-VE は、LXC を使ったコンテナ環境も用意されています。コンテナ環境では、kernel は 仮想化環境のベースOSのものを使いますが、ユーザランドはopenSUSE のものが使われます。この記事を書いている時点で openSUSE 15.2 相当のコンテナ環境があったので使ってみることにしました。
openSUSE 15.2 のコンテナ環境は、Proxmox VE 標準で用意されていますので、それをWebインタフェースから選択するだけでダウンロード、インストールができます。
インストール完了後は、パッケージの総数は181個でした。見てみましたが、最低限の動作をするために必要なものだけしかない状態です。ssh,sshもないですし、yastも入っていませんでした。ほとんど何も出来ないと行っていいでしょう。/ ディレクトリも 213M しか使っていませんでした。必要最低限のユーザランドを一気に入れてしまうFreeBSD よりまさらにコンパクトです。さすがにzypper は入っていましたので、パッケージの追加は出来ます。
そこで、まずは zypper update を行ったのち、openssh を入れ、さらに yast (パッケージとしてはyast2) を入れてみました。
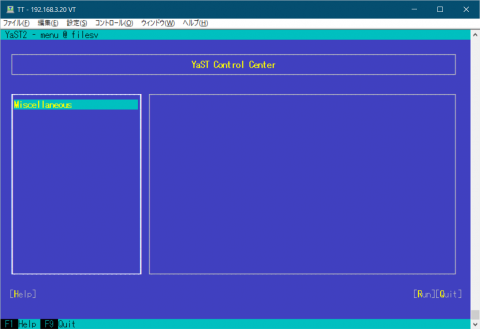
yast を入れた直後の画面は図1のようになります。
図1 yast を入れた直後の yast の画面 何もないですね。この時点では、yast2-ycp-ui-bindings, yast2-perl-bindings,yast2,yast2-core,yast2-xml,yast2-logs,yast2-ruby-bindings,yast2-hardware-detection,yast2-pkg-binding というものしか入っていません。 yast のサブメニューに対応するパッケージを何も入れていないため、何もないわけです。
そこで、他のサーバを参考にしつつ、yast パッケージを入れてみることにしました。取りあえずはSamba サーバにしたいため、yast2-samba-server を入れることにしました。すると、yast2-samba-client を含め、関連するパッケージが42個も入りました。
続いてSamba本体のパッケージ Samba を入れます。ここでも40パッケージが追加されました。
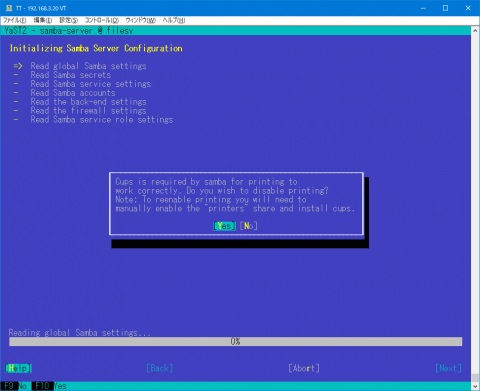
さて、Sambaをyast で設定するためには少し準備が必要です。useradd でユーザの追加、共有ディレクトリの準備とアクセス権の設定をします。また、pdbedit でSamba用ユーザの登録をします。その後に yast で Sambaの設定をします。しかし、起動すると、図2のように cups を無効にするかどうかを聞いてきます。
図2 capsは不要 今はSamba経由で印刷することはほぼ皆無なので、最初から無効にしておいてもいいんじゃないかと思うのですけどね。
さて、一通り設定が終わり、Sambaを起動しようとしたのですが、smbdがなぜか起動しません。ログを見ると、
ERROR: failed to setup guest info.
と言うエラーが出ていました。これはSambaが使うゲストユーザの定義がないということでした。調べて見ると、普通OSをインストールしたときには、nobody というユーザが作られているのですが、このLXC環境では入っていなかったのでした。そこで、uid 65534,gid 65533 の nobody を作りました。これでsmbの起動はOKとなりました。
Category
openSUSE ,
Tips ,
サーバ ,
仮想化 |
受け付けていません
5 / 10 « 先頭 « ... 3 4 5 6 7 ... 10 ... » 最後 »